A key property of a nondistributed array is that some drives within the array are designated as spare drives. In a nondistributed array configuration, the spare drives are used only when other drives in the array fail.
A nondistributed array can contain 2 - 16 drives; several arrays create the capacity for a pool. For redundancy, spare drives ("hot-spares") are allocated to assume read or write operations if any of the other drives fail. The rest of the time, the spare drives are idle and do not process requests for the system. When a member drive fails in the array, the data can only be recovered onto the spare as fast as that drive can write the data. Because of this bottleneck, rebuilding the data can take many hours as the system tries to balance host and rebuild workload. As a result, the load on the remaining member drives can significantly increase. The latency of I/O to the rebuilding array is affected for this entire time. Because volume data is striped across MDisks, all volumes are affected during the time it takes to rebuild the drive.
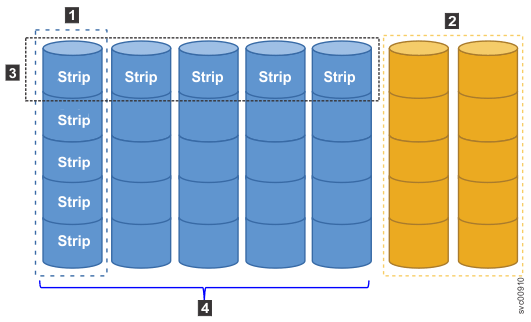
Examples of an array
- 1 An active drive.
- 2 Spare drives; both drives are inactive.
- 3 Stripe of data, which is composed of individual strips of data.
- 4 Stripe width, which equals the array width; only the active drives are included in the stripe width.
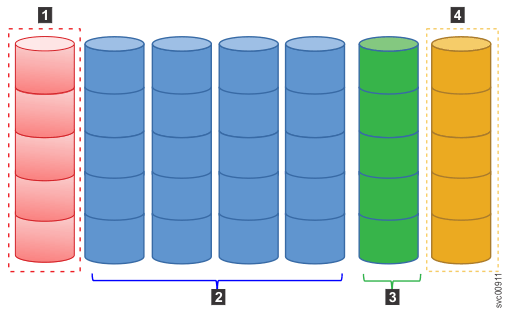
- 1 Failed drive
- 2 Remaining active drives, from which the recovered data is read.
- 3 Recovered data is written to one spare drive.
- 4 Remaining spare drive remains unused and idle.
Supported RAID levels
The system supports the following RAID levels: RAID 0, RAID 1, RAID 5, RAID 6, and RAID 10.
- RAID 0 arrays have no redundancy and do not support hot-spare takeover.
- RAID 1 provides disk mirroring, which duplicates data between two drives. A RAID 1 array is internally identical to a two-member RAID 10 array.
- RAID 5 arrays stripe data over the member drives with one parity strip on every stripe. RAID 5 arrays have single redundancy with higher thin-provisioning than RAID 10 arrays, but with some performance penalty. RAID 5 arrays can tolerate the failure of one member drive.
- RAID 6 arrays stripe data over the member drives with two parity strips on every stripe. A RAID 6 array can tolerate any two concurrent member drive failures.
- RAID 10 arrays stripe data over mirrored pairs of drives. RAID 10 arrays have single redundancy. The mirrored pairs rebuild independently. A member from every pair can be rebuilding or missing at the same time. RAID 10 combines the features of RAID 0 and RAID 1.
Table 1 compares the characteristics of the RAID levels.
| Level | Drive count (DC)1 | Approximate array capacity | Redundancy2 |
|---|---|---|---|
| RAID 0 | 1 - 8 | DC * DS3 | None |
| RAID 1 | 2 | DS | 1 |
| RAID 5 | 3 - 16 | (DC - 1) * DS | 1 |
| RAID 6 | 5 - 16 | Less than (DC - 2) * DS | 2 |
| RAID 10 | 2 - 16, evens | (DC/2) * DS | 14 |
Array initialization
When an array is created, the array members are synchronized with each other by a background initialization process. The array is available for I/O during this process. Initialization has no impact on availability due to member drive failures.
Drive failures and redundancy
If an array has the necessary redundancy, a drive is removed from the array if it fails or access to it is lost. If a suitable spare drive is available, it is taken into the array, and the drive then starts to synchronize.
Each array has a set of goals that describe the preferred location and performance of each array member. If a drive fails, a sequence of drive failures and hot-spare takeovers can leave an array unbalanced; that is, the array might contain members that do not match these goals. When appropriate drives are available, the system automatically rebalances such arrays.
Rebalancing is achieved by using concurrent exchange, which migrates data between drives without impacting redundancy.
You can manually start an exchange and the array goals can also be updated to facilitate configuration changes.
Spare drive protection and goals
Array commands have an attribute that is called spare_protection, which you can use to specify the number of good spares for an array member. The array attribute spare_protection_min is the minimum of the spare protection of the members of the array.
The array attribute spare_goal is the number of good spare drives that are needed to protect each array member. This attribute is set when the array is created and can be changed with the charray command.
If the number of good spare drives that an array member is protected by falls below the array spare goal, you receive event error 084300.
Slow write priority settings
When a redundant array level is doing read/write I/O operations, the performance of the array is bound by the performance of the slowest member drive. When drives do internal ERP processes, if the SAS network is unstable, or if too much work is being driven to the array, performance to member drives can be far worse than usual. In this situation, arrays that offer redundancy can accept a short interruption to redundancy to avoid writing to, or reading from, the slow component. Writes that are mapped to a poorly performing drive are committed to the other copy or parity, and are then completed with good status (assuming no other failures). When the member drive recovers, the redundancy is restored by a background process of writing the strips that were marked out of sync while the member was slow.
This technique is governed by the setting of the slow_write_priority attribute of the array, which defaults to latency. When set to latency, the array is allowed to become out of sync in an attempt to smooth poor member performance. You can use the charray command to change the slow_write_priority attribute to redundancy. When set to redundancy, the array is not allowed to become out of sync. However, the array can avoid suffering read performance loss by returning reads to the slow component from redundant paths.
When the array uses latency mode or attempts to avoid reading a component in redundancy mode, the system evaluates the drive regularly to assess when it becomes a reliable part of the system again. If the drive never offers good performance or causes too many performance failures in the array, the system fails the hardware to prevent ongoing exposure to the poor-performing drive. The system fails the hardware only if it cannot detect another explanation for the bad performance from the drive.
Drive offline incremental rebuild
When a drive goes offline in an internal RAID array, the system does not immediately replace it with a hot-spare drive. For a 60-second period, the drive marks where new writes occurred. If the drive reappears online, it completes an "incremental rebuild" of the places where the writes occurred rather than a full component rebuild. This technique occurs regardless of the array's slow_write_priority setting because avoiding a spare takeover is desirable to maintain the highest system availability.
Drive replacement
A drive with a lit fault LED indicates that the drive was marked as failed and is no longer in use by the system. When the system detects that such a failed drive is replaced, it reconfigures the replacement drive to be a spare drive. The failed drive that was replaced is automatically removed from the configuration. The new spare drive is then used to fulfill the array membership goals of the system.